Short version:
- Tools for thought promise to let you centralize and hyperlink all your data.
- In practice 95% of the use cases can be naturally unbundled into disjoint apps, and the lack of centralization and cross-app hyperlinking has no real negative effects.
There’s a joke in game development that there’s two kinds of game devs: those who write engines, and those who make games. The people who make the engines do it for the intellectual pleasure of discovering a beautiful algebra of vectors, scenes, entities, and events; and watching a beautiful, crystalline machine in operation. The actual game—which is never finished, rarely started—is an afterthought. Of course you wouldn’t make a game. That would be parochial. The engine was the point. People who want to make games just download Unity and push through the horror.
I’ve written something like six or seven personal wikis over the past decade. It’s actually an incredibly advanced form of procrastination1. At this point I’ve tried every possible design choice.
-
Lifecycle: I’ve built a few compiler-style wikis: plain-text files in a
gitrepo statically compiled to HTML. I’ve built a couple using live servers with server-side rendering. The latest one is an API server with a React frontend. -
Storage: I started with plain text files in a git repo, then moved to an SQLite database with a simple schema. The latest version is an avant-garde object-oriented hypermedia database with bidirectional links implemented on top of SQLite.
-
Markup: I used Markdown here and there. Then I built my own TeX-inspired markup language. Then I tried XML, with mixed results. The latest version uses a WYSIWYG editor made with ProseMirror.
And yet I don’t use them. Why? Building them was fun, sure, but there must be utility to a personal database.
At first I thought the problem was friction: the higher the activation energy to
using a tool, the less likely you are to use it. Even a small amount of friction
can cause me to go, oh, who cares, can’t be bothered. So each version gets
progressively more frictionless2. The latest version uses a WYSIWYG editor
built on top of ProseMirror (it took a great deal for me to actually give in to
WYSIWYG). It also has a link to the daily note page, to make journalling
easier. The only friction is in clicking the bookmark to localhost:5000. It is
literally two clicks to get to the daily note.
And yet I still don’t use it. Why? I’m a great deal more organized now than I was a few years ago. My filesystem is beautifully structured and everything is where it should be. I could fill out the contents of a personal wiki.
I’ve come to the conclusion that there’s no point: because everything I can do with a personal wiki I can do better with a specialized app, and the few remaining use cases are useless. Let’s break it down.
Unbundling
The following use cases are very naturally separable:
-
Journalling: 86% of the nodes in my personal wiki are journal entries. Mostly there’s no reason for them to be there, they are rarely linked to by anything. I have this fallacious view that I have to use the app to justify the time investment, therefore I should use it every day, and the obvious thing you can do every day is write a daily entry that has, say, the tasks for today along with journal-like text. Rarely do journal entries link to anything except incidentally.
-
Todo Lists: I used to write todo lists in the daily entries in my personal wiki. But this is very spartan: what about recurring tasks, due dates, reminders, etc.? Now I am a very happy user of Todoist (which has increased my productivity at least 150%) and I’m not looking back.
-
Learning: if you’re studying something, you can keep your notes in a TfT. This is one of the biggest use cases. But the problem is never note-taking, but reviewing notes. Over the years I’ve found that long-form lecture notes are all but useless, not just because you have to remember to review them on a schedule, but because spaced repetition can subsume every single lecture note. It takes practice and discipline to write good spaced repetition flashcards, but once you do, the long-form prose notes are themselves redundant.
I also tried writing notes to ensure I understand something first, and then translating them to flash cards. I’ve found that, usually, all this does is add an extra layer of friction with no benefit.3
I also find that long-form study notes are a form of procrastination. I start re-organizing the headings, playing with the LaTeX to make everything look beautiful and structured, to really get the conceptual organization right so that when future me, who has forgotten everything, reads the notes back, he can easily re-acquire the information because of how well it is presented. This is planning for failure. Spaced repetition is insanely effective, even more so when you get the hang of writing flashcards that work for you.
RemNote combines long-form prose notes and flashcards in the same interface. The result is that both look like a mess.
-
Contacts: if you have a page for a person, with data about them, you can then link to them: when you mention them in journal entries for example, or in writing meeting notes. I find that this is pointless. You know who
[[John Doe]]refers to. Just use Google Contacts or a spreadsheet. -
Fiction Writing: I actually started writing The Epiphany of Gliese 581 in my personal wiki, with fragments and chapters in separate pages, but I quickly moved to a git repo with Markdown files because 1) I could compile the disparate files into a single PDF or HTML file for review, and 2) using git for version control (rather than my personal wiki’s native change tracking) makes a lot more sense for writing projects.
And you could argue that I could have stayed in my personal wiki by implementing support for transclusion (to assemble all the fragments into one view) and improved the version control UI. But this advice can be applied equally to every domain I attack with a personal TfT and for which it is lacking: just write a plugin to do X. The work becomes infinite, the gains are imaginary. You end up with this rickety structure of plugin upon plugin sitting on top of your TfT, and UX typically suffers the death by a thousand cuts.
-
Process Notes: e.g. “how do I do X in Docker”. I often have cause to write notes like this and can never quite think of where to put them. But this can’t be a genuine use case for a tool for thought because there’s very little need to create links between process notes. So this is just a matter of finding somewhere to put them in the filesystem or in a note-taking app.
-
Organizing Legal Documents: like immigration papers or medical test results. A decent folder structure and a few spreadsheets is all it takes in practice.
-
Lists: of things you own, people you know, places you’ve lived in, education history, work history, the administrativia of life. Spreadsheets work just fine for this and there is very rarely any genuine need to link from one to another.
What is left?
-
Collection Management: this is an area where the software solutions are strangely very lacking.
I have a Calibre library for books. I have a Zotero library for papers. I sometimes think about merging the former into the latter, which is more general and has a cleaner UI, but there’s no urgent need to do so. I also have folders with music, games, interactive fiction games, RPG PDFs, board game rulebook PDFs, and art.
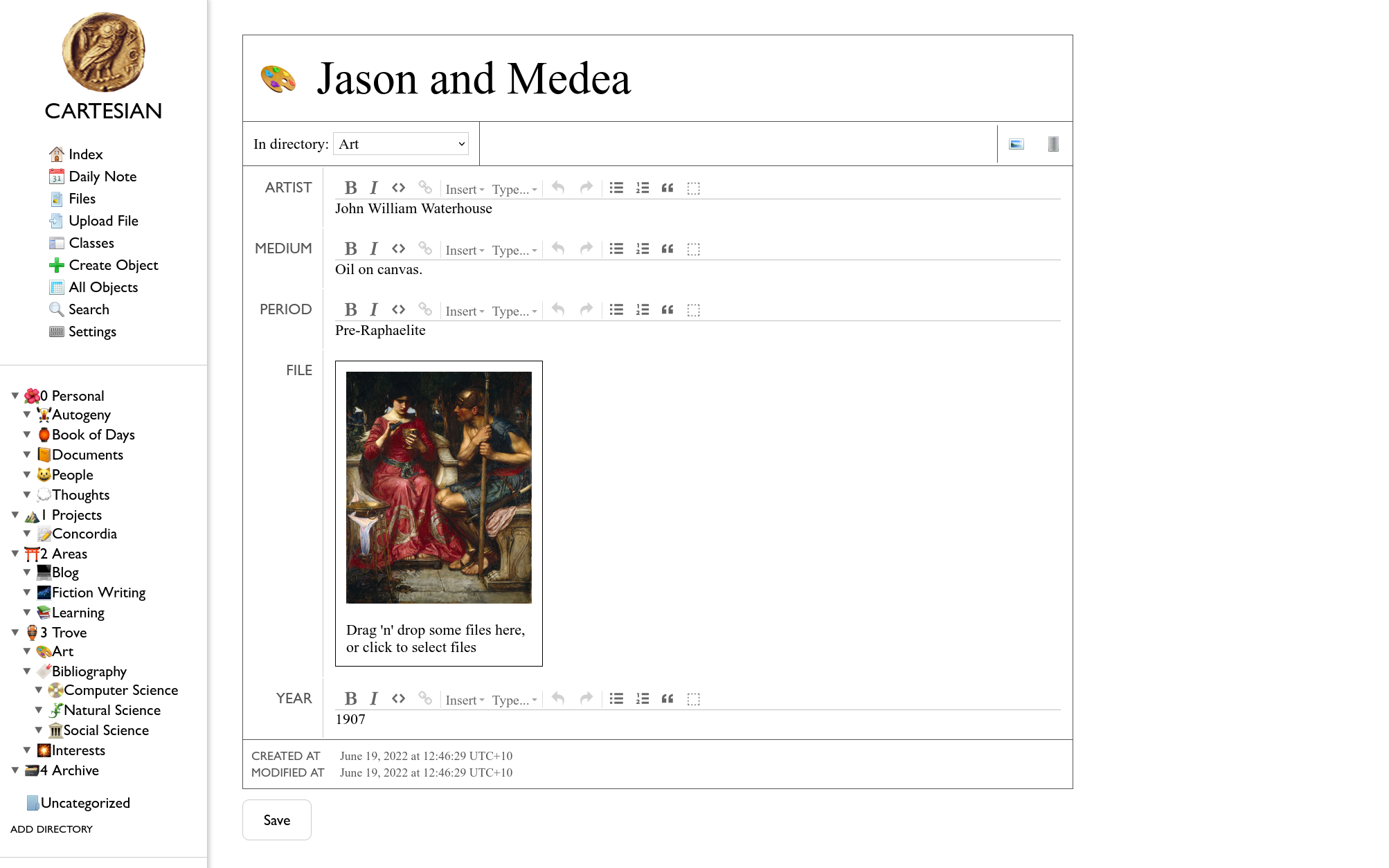
Organizing collections with the filesystem is difficult, because of the hierarchical nature of the filesystem4: do I file Nanosystems under “Chemistry” or “Eric Drexler” or “Textbooks” or “1992”? Do I file The Mermaid under “John William Waterhouse”, “Painting”, “Edwardian Era”, “Pre-Raphaelite Art”? Any categorization is defensible, and any categorization makes it harder to browse by an alternative scheme5. I need tags, that is: I need a database.
And there is a void in app-space, where there should be an app that subsumes Calibre and the rest, but inexplicably it doesn’t exist6. And it’s so obvious what it should be.
It should be, essentially, an SQLite frontend with a fancy interface. You can define record templates (like
BookorPersonorSongorPaper) having typed fields (e.g.Title: String,PDF: File,Authors: List[Link[Author]], field types can be simple data like strings or dates, or links to other records, or lists of links, or a star rating, etc.), and then add records to your collection. You can put records in hierarchical folders, but you can also retrieve them with search and tags.The closest thing to this is a KDE app called Tellico that I’ve never heard anyone talk about using.
{kind=link}
When you take out everything that is better served by an app or plain old folder structure, all you’re left with is collection management. So instead of building a personal wiki I should just build a “generalized Calibre”.
The Uselessness of Scale
So I often wonder: what do other people use their personal knowledge bases for? And I look up blog and forum posts where Obsidian and Roam power users explain their setup. And most of what I see is junk. It’s never the Zettelkasten of the next Vannevar Bush, it’s always a setup with tens of plugins, a daily note three pages long that is subdivided into fifty subpages recording all the inane minutiae of life. This is a recipe for burnout.
People have this aspirational idea of building a vast, oppressively colossal, deeply interlinked knowledge graph to the point that it almost mirrors every discrete concept and memory in their brain. And I get the appeal of maximalism. But they’re counting on the wrong side of the ledger. Every node in your knowledge graph is a debt. Every link doubly so. The more you have, the more in the red you are. Every node that has utility—an interesting excerpt from a book, a pithy quote, a poem, a fiction fragment, a few sentences that are the seed of a future essay, a list of links that are the launching-off point of a project—is drowned in an ocean of banality. Most of our thoughts appear and pass away instantly, for good reason.
The Single Graph Fallacy
There’s this pervasive idea that a tool for thought—a hypermedia database with bidirectional links—can be a universal database of “you”, and other apps can be built on top of that data, using plugins. There are two pros here:
-
Centralization of Data: everything is one central place, rather than spread out across your filesystem, Dropbox, and database rows in six different proprietary apps.
-
Hyperlinking: you can link your data pervasively:
- Link spaced repetition cards to their corresponding theory notes.
- Link date metadata to the journal entry for that date.
- Link calendar events to tasks, dates, people, and projects.
Obsidian does this: it has some 700 plugins for this reason. There’s plugins for todo lists, calendar integration, spaced repetition, whatever.
The main drawback is the user experience for this plugin-based app universe is always going to be inferior to the user experience for domain-specific apps. It’s very rare that an app does plugins right. It always feels janky7.
But the main drawback is: you don’t need it. The idea of having this giant graph where all your data is hyperlinked is cute, but in practice, it’s completely unnecessary. Things live in separate apps just fine. How often, truly, do you find yourself wanting to link a task in your todo list app to a file in Dropbox? And if you do manage to build this vast web of links: how often is each link actually followed?
(Aside: in the web, it makes sense that links should reflect potential, since you don’t know what people reading your document will want to follow. But in a personal database it makes a lot more sense that links should follow usage: they should be a crystallization of the trails you’ve followed, rather than an a-priori structure that you impose before usage.)
The final argument against this is feasibility. Tiago Forte writes:
… you will always need to use multiple programs to complete projects. You may use a centralized platform like Basecamp, Asana, Jira, or Zoho, but technology is advancing too quickly on too many fronts for any one company to do every single function best.
And he is absolutely right, unless you want to rewrite the entire universe on top of your TfT. The “one graph database” is an unproductive, monistic obsession.
A final note: I find that upwards of 80% of the links in my wikis are essentially structural, they basically replicate folder structures. The rest are “incidental reference” links: I’m writing a journal entry saying I’m working on project X, so I add a link to project X, out of some vague feeling of duty to link things. And it’s pointless.
The idea of hyperlinks as “generative”, as a path that can follow and acquire new ideas from the random collision of information, mostly applies to the web, not to personal databases where all the content is written by you.
My Current Wiki

(The text is a quote from Accelerando.)
The natural conclusion of most tools for thought is a relational database with rich text as a possible column type. So that’s essentially what I built: an object-oriented graph database on top of SQLite.
My current personal wiki is called Cartesian (after the Cartesian theatre, since I initially thought to build something much more ambitious). The conceptual vocabulary is simple: there’s objects, classes, and links.
- Objects are the nodes in the database: they have a globally-unique title and a set of properties, which are typed key-value pairs.
- Every object conforms to a class, which specifies what properties it has and their types. Property types can be: rich text, a link to a file, a boolean, a link to another object, or a list of links.
- Links go from one object property to another object (there’s no block references). Notion inspired a lot of this.
Most personal wikis are just a special case of this, where there’s a single
class with a single text property. And, unsurprisingly, the main class I use is
Note, which has a single rich text property called Text.
Initially I had an idea to build classes for managing bibliographies and other collections, e.g.:
- A
Bookclass to replace Calibre, with fields like:Authors: a list of links to the author objects (thanks to bidirectional linking, going to an author’s page shows you the list of all objects that link to it, i.e. the things they’ve authored).PDF: a file link.
- A
Paperclass to replace Zotero, with the fields you’d expect. - An
Artclass to manage my art collection, with fields likeArist,Year,Period,Genre,File. - Classes to organize my legal documents, e.g. a
Documentclass that has a file and a text property for notes.
But I’ve largely used it for journalling and brief text notes, like my journal:
And study notes:
Here’s an example of how you’d use it to organize an art collection:
The barriers to using it as The One Database are:
- Activation Energy: migrating everything from my filesystem, from Calibre, from Zotero, from my browser bookmarks, etc. is a huge process. Even just migrating stuff from Calibre to the database would require me to write a script because my Calibre library is so huge.
- UI: replacing the filesystem and most of my domain-specific apps means the wiki’s UI has to be stellar. It has to support searching, filtering, sorting, viewing collections of objects in different modes (list, table, gallery, etc., like in Notion). Getting this to the UX sweet spot where things are frictionless enough to use the app productively requires a significant time investment.
- Pointlessness of Organization: my Calibre and Zotero libraries are a mess. But is that bad? Is there any point to organizing them? I can always find what I need, either by searching or browsing, because I have a spatial sense of where each book is in Calibre’s big grid view. If I went through everything in Calibre and Zotero, and fixed the titles, added missing authors, publishers, publication years, fixed the cover images—what then? What have I gained? Nothing. It is a waste of time to organize things too much.
- Uncertain Payoff: silver bullets are rare, and it’s possible that after making a titanic effort to migrate all my data and build a great UI, the result of very underwhelming.
Conclusion
Having reached the trough of disillusionment: what’s next? I think I might clean up Cartesian and release it as a kind of “generalized Calibre”, for people who want to manage their disparate collections.
Or I might try writing personal wiki #8 or so, since, while writing this post, I got a whole lot of new ideas, so I might allocate some time during the holidays to pushing that boulder up again.
Footnotes
-
In college, when I should have been studying lecture notes, I was building a personal wiki so I could take better, more structured lecture notes. ↩
-
For example: XML soothes my autism, and the extensibility makes it easier to add new features8, but it’s a pain to author, especially when you just want to jot down some very quick bullet-type notes. In Markdown you can write:
- foo - bar - bazThe equivalent XML:
<ul> <li> <p> foo </p> </li> <li> <p> bar </p> </li> <li> <p> baz </p> </li> </ul>By the time you’re done with this Shakespearean soliloquy, you’ve lost whatever train of thought you were trying to capture. Meanwhile, in another Everett branch, your wiser, Markdown-using twin has already finished writing and moved on to doing, while you marvel at the crystalline strictness, the sheer extensibility of your DTD schema. ↩
-
I sometimes use a small scratchpad to serialize my mental model of something until I understand it, and then move it to flashcards. But the crucial distinction here is: there aren’t two big stages, one where I just take prose notes, and one where I translate all the notes to flashcards. It’s like agile vs. waterfall: the notes should become flashcards as early as possible, not after you’re done taking all of the notes. ↩
-
This is a great blog post on the difficulties and limitations of hierarchical filesystems. ↩
-
If you’re going to tell me to use symbolic links or, God help me, some FUSE-based tag filesystem thing, please don’t. I mean this with all the love in the world. I’m not 17 anymore, I don’t have time for, “Mom, cancel my appointments for the rest of the day, ZFS is broken”. I don’t want my TfT to be a kernel driver, I want things to be simple and portable. ↩
-
Notion is actually good for this, except that uploading multiple gigabytes of PDFs one by one is inconvenient. But if a tool is to be my second brain, it can’t live on somebody else’s computer. ↩
-
I moved from Anki to Mochi for this reason: Mochi does out of the box what I need plugins to do in Anki, and managing Anki plugins is a huge pain, and the plugin UI is always broken. Mochi has fewer features, but a nicer UI (Anki is ugly as sin), and the UI trumps the features since spaced repetition is about building a habit, for which good UX is necessary. ↩
-
One of my personal wikis exploited this. There was a
<graphviz>element where you could enter the contents of a.dotfile and it would automatically render that to a PNG and display it on the page. In theory this would make it easier to build e.g. mind maps, without having to separately create a.dotfile, manually save it to PNG, add it to the wiki, and embed it. I never used it. ↩