Austral is a new systems programming language. It features linear types for safe, compile-time memory and resource management; capability-based security to prevent supply chain attacks; and strong modularity. It is designed with fits-in-head simplicity as the goal.
A while back I wrote a post on the lessons I learnt writing the Austral compiler. This post is a more detailed walkthrough of the bootstrapping compiler for Austral.
Contents
Why OCaml?
OCaml is a great language for writing compilers. Like Haskell and other languages in the ML family, its support for sum types and pattern matching makes it very easy to write tree transformations, which is what most of a compiler is. Like Haskell, you can write functional code; unlike Haskell, you can mutate and perform side effects pervasively. And OCaml has Menhir, a really outstanding parser generator on par with Java’s ANTLR.
Requirements
-
Short Time to MVP: it’s a bootstrapping compiler, not a production compiler, so the goal is to be able to get to “Hello, world!” as early as possible. Consequently the implementation should be as simple and quick to implement as possible. As a result the compiler is just 12,000 lines of straightforward grugbrained OCaml.
-
Readable: the compiler is written in the least fanciful style of OCaml imaginable. There’s no transdimensional optical profunctors or whatever Haskellers are up to.
-
Hackable: languages evolve most in their early stages. Writing a highly-optimized production compiler would be premature if you end up having to throw out most of it because you changed your mind about some central language feature. So the compiler is designed to be hackable and gradually evolvable, at the expense of semantics-specific optimizations and thus performance.
-
Correctness: the compiler is a reference implementation, so correctness matters above most other things.
Limitations
The above requirements, which prioritize certain dimensions over others, have some consequences:
- No Separate Compilation: for simplicity, the compiler is a whole-program compiler. It compiles all source files, in order, from the first one to the last one. Separate compilation is not supported.
- Batch Compilation: also for simplicity, the compiler is a batch compiler, so there’s no incremental compilation or external symbol database. Everything happens in one long pipeline.
- Performance: much of the compiler is written in an easily-testable functional style, potentially at the expense of performance.
- Backend: the backend is just C, which is in turn compiled by a C compiler (though it would not be too much work to “upgrade” this to compile to LLVM IR).
High-Level View
The following diagram shows the flow of data in the compiler. Blue nodes are source representations, green nodes are compiler passes:
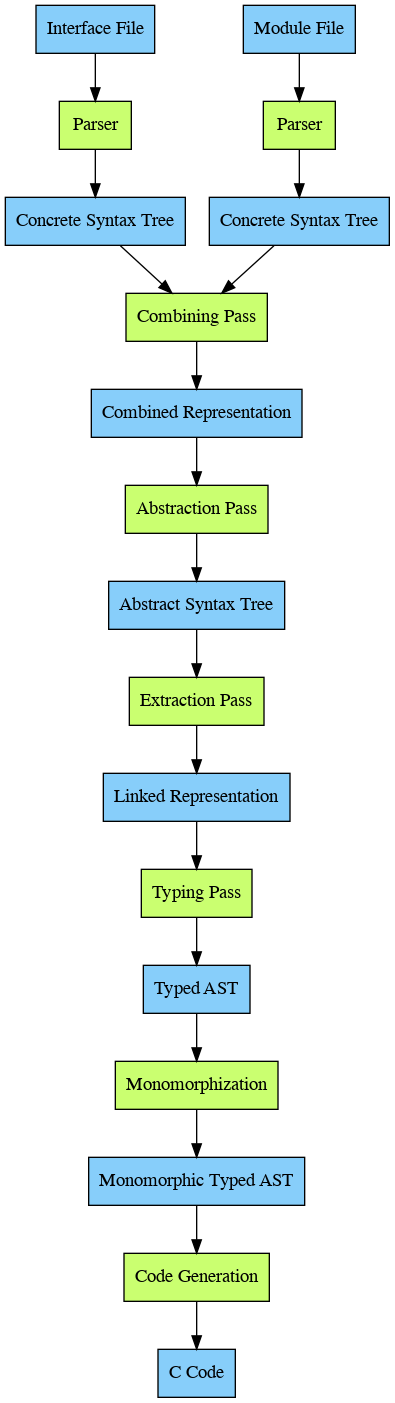
Frontend
The frontend is the parser, which takes source code and turns it into the earliest tree representation: the concrete syntax tree. After that there’s the combining pass, where the separate module interface and module body are combined into a single object. The parser is written in Menhir, a powerful parser generator for OCaml, and the lexer is writting in ocamllex.
The Concrete Syntax Tree
The concrete syntax tree is the first tree representation in the compiler, and the one closest to the original source code. It’s defined in the Cst module and it’s just a set of types. The main four types represent:
- Module interface declarations.
- Module body declarations.
- Statements.
- Expressions.
And there’s other auxiliary types. As an example, the sum type that represents expressions looks like this:
and cexpr =
| CNilConstant of span
| CBoolConstant of span * bool
| CIntConstant of span * string
| CFloatConstant of span * string
| CStringConstant of span * string
| CVariable of span * identifier
| CArith of span * arithmetic_operator * cexpr * cexpr
| CFuncall of span * identifier * concrete_arglist
| CComparison of span * comparison_operator * cexpr * cexpr
| CConjunction of span * cexpr * cexpr
| CDisjunction of span * cexpr * cexpr
| CNegation of span * cexpr
| CIfExpression of span * cexpr * cexpr * cexpr
| CPath of span * cexpr * concrete_path_elem list
| CEmbed of span * typespec * string * cexpr list
| CDeref of span * cexpr
| CTypecast of span * cexpr * typespec
| CSizeOf of span * typespec
| CBorrowExpr of span * borrowing_mode * identifier
Every case has a span, which carries source position information, and
optionally other data. For example, an arithmetic expression a+b is
represented by an instance of CArith, which has four values: the source span,
the arithmetic operator +, and the expressions a and b.
Analogously, cstmt is the type of concrete statements:
and cstmt =
| CSkip of span
| CLet of span * identifier * typespec * cexpr
| CDestructure of span * concrete_binding list * cexpr
| CAssign of span * concrete_lvalue * cexpr
| CIf of span * cexpr * cstmt * cstmt
| CCase of span * cexpr * concrete_when list
| CWhile of span * cexpr * cstmt
| CFor of span * identifier * cexpr * cexpr * cstmt
| CBorrow of {
span: span;
original: identifier;
rename: identifier;
region: identifier;
body: cstmt;
mode: borrowing_mode
}
| CBlock of span * cstmt list
| CDiscarding of span * cexpr
| CReturn of span * cexpr
Lexing
Lexing turns a string into a stream of tokens. For example, a code fragment like
if x > 0 gets turned into the token stream IF, IDENTIFIER "x", GREATER_THAN,
DEC_CONSTANT "0".
Tokens are defined, strangely, in the parser. Tokens that carry no information (like symbols and language keywords) are defined like this:
/* Brackets */
%token LPAREN
%token RPAREN
%token LBRACKET
%token RBRACKET
%token LCURLY
%token RCURLY
Tokens that carry a value (like integer literals or identifiers) are defined like this:
/* Strings and docstrings */
%token <string> STRING_CONSTANT
%token <string> TRIPLE_STRING_CONSTANT
/* Identifiers and constants */
...
%token <string> DEC_CONSTANT
%token <string> HEX_CONSTANT
%token <string> BIN_CONSTANT
%token <string> OCT_CONSTANT
%token <string> CHAR_CONSTANT
%token <string> FLOAT_CONSTANT
%token <string> IDENTIFIER
Every %token declaration essentially corresponds to the constructors of a
token sum type (which you don’t define, but the parser defines it internally):
type token =
| LPAREN
| RPAREN
...
| IDENTIFIER of string
| STRING_CONSTANT of string
The main part of the lexer is the token rule, which associates regular
expressions with code that evaluates to a token:
rule token = parse
(* Comments *)
| comment { advance_line lexbuf; token lexbuf }
(* Brackets *)
| "(" { LPAREN }
| ")" { RPAREN }
| "[" { LBRACKET }
| "]" { RBRACKET }
| "{" { LCURLY }
| "}" { RCURLY }
(* Arithmetic operators *)
| "+" { PLUS }
| "-" { MINUS }
| "*" { MUL }
| "/" { DIV }
(* ... *)
| identifier { IDENTIFIER (Lexing.lexeme lexbuf) }
(* etc. *)
| whitespace { token lexbuf }
| newline { advance_line lexbuf; token lexbuf }
| eof { EOF }
| _ {err ("Character not allowed in source text: '" ^ Lexing.lexeme lexbuf ^ "'") }
Parsing
Parsing turns a sequence of tokens into a tree, specifically into the concrete syntax tree. The parser is written in Menhir, which is simple to use although the documentation is lacking: you just write a BNF grammar, and tell it how the right-hand side of each production rule should map to a CST instance.
For example: in the cexpr type (the CST type for Austral expressions), the
constructor for function calls looks like this:
type cexpr =
(* ... *)
| CFuncall of span * identifier * concrete_arglist
That is, it has a code span, the function name, and the argument list, which in turn is defined:
type concrete_arglist =
| ConcretePositionalArgs of cexpr list
| ConcreteNamedArgs of (identifier * cexpr) list
With one case for positional argument lists like (x,y,z) and another for named
argument lists like (foo => a, bar => b).
The parser rule for function calls is:
funcall:
| identifier argument_list { CFuncall (from_loc $loc, $1, $2) }
;
There are two parts to this: the (E)BNF part and and the OCaml code in curly
braces. The BNF says the funcall non-terminal is an identifier followed by
an argument_list.
When this is encountered, this parser will execute the code in the curly
braces. This creates a cexpr value through the CFuncall constructor. $loc
is a special variable that has the parser’s current location in the input
stream, from_loc turns this value into a span. $1 and $2 refer
respectively to identifier and argument list (it’s also possible to name
them, when that increases clarity).
The rules for argument lists work the same way:
argument_list:
| LPAREN positional_arglist RPAREN { ConcretePositionalArgs $2 }
| LPAREN named_arglist RPAREN { ConcreteNamedArgs $2 }
| LPAREN RPAREN { ConcretePositionalArgs [] }
;
positional_arglist:
| separated_list(COMMA, expression) { $1 }
;
named_arglist:
| separated_list(COMMA, named_arg) { $1 }
;
The last two show a useful feature of Menhir: parameterized rules. In this case
the pattern of rules for parsing comma-separated lists has been abstracted away
and we can just use separated_list(COMMA, <rule>).
Combining Pass
In the combining pass, the separate CST representations for the module interface and module body are combined into one object, that has one collection of declarations, augmented with visibility information.
For example, given the following interface:
module Foo is
constant Pi: Float32;
record Pair: Free is
x: Int32;
y: Int32;
end;
type Quux: Free;
function zero(): Nat64;
end module.
And the following body:
module body Foo is
constant Pi: Float32 := 3.14;
union Quux: Free is
case Up;
case Down;
end;
function zero(): Nat64 is
return 0;
end;
function infinite(): Unit is
return infinite();
end;
end module body.
The combined representation, if rendered as code, might look something like this:
combined module Foo is
public constant Pi: Float32 := 3.14;
public record Pair: Free is
x: Int32;
y: Int32;
end;
opaque union Quux: Free is
case Up;
case Down;
end;
public function zero(): Nat64 is
return 0;
end;
private function infinite(): Unit is
return infinite();
end;
end combined module.
Core
The core is the largest part of the compiler. It contains the environment, where declarations are stored, and the type checking, linearity checking, and monomorphization passes.
Errors
Compiler errors are represented as structured values, that contain information about where the error occurred as well as the error message:
(** An Austral compiler error. The module name, span, and source context rarely
have to be passed in explicitly: they are added where the error is throw in
the context of {!adorn_error_with_span}. *)
type austral_error = AustralError of {
module_name: module_name option;
(** The name of the module where the error occurred, if available. *)
kind: error_kind;
(** The error kind. *)
text: err_text;
(** The error text. *)
span: span option;
(** The source span where the error happened, if available. *)
source_ctx: source_ctx option;
(** The source code where the error happened, if available. *)
}
The error_kind is something like a “typed title”:
(** Represents a category of errors. *)
type error_kind =
| GenericError
(** A generic error. This should be gradually phased out. *)
| ParseError
(** A parse error. *)
| CliError
(** An error with the user's command line arguments. *)
| TypeError
(** A type error. *)
| LinearityError
(** Signalled when code breaks the linearity rules. *)
| DeclarationError
(** An error in the structure of a declaration. *)
| EntrypointError
(** An error with the definition of the program entrypoint. *)
| InternalError
(** An internal error in the compiler. *)
The error message, too, is structured. This is both to reduce the amount of string-fiddling done at error-reporting time, but also to allow me to add HTML error reporting in the future:
(** The contents of an error message. *)
type err_text = text_elem list
(** An individual error text element. *)
and text_elem =
| Text of string
(** Human-readable prose. *)
| Code of string
(** Austral text, like the name of an identifier or a type. *)
| Break
(** A paragraph break. *)
While the errors are structured values, OCaml doesn’t have monadic error handling, so errors are simply carried by exceptions:
(** The exception that carries Austral errors. *)
exception Austral_error of austral_error
Thrown by the austral_raise function, which takes the error kind and the error
text and raises an exception:
let austral_raise (kind: error_kind) (text: err_text): 'a =
let error: austral_error =
AustralError {
module_name = None;
kind = kind;
text = text;
span = None;
source_ctx = None;
}
in
raise (Austral_error error)
Why is the metadata empty? Because it’s added up the call stack. If we had to
pass source position/module information everywhere an error is reported, the
code would become incredibly noisy. So instead we have the adorn_* functions:
(** Run the callback, and if it throws an error that doesn't have a module name,
put the given module name in the error and rethrow it. *)
val adorn_error_with_module_name : module_name -> (unit -> 'a) -> 'a
(** Run the callback, and if it throws an error that doesn't have a span, put
the given span in the error and rethrow it. *)
val adorn_error_with_span : span -> (unit -> 'a) -> 'a
These take some metadata and run a callback, and catch any Austral_error
exceptions that are raised. If the error doesn’t have a span or a module name,
it gets added and the exception is re-raised.
Code should use adorn_error_with_span whenever it has source position
information, and in that way, error messages will have the most specific source
position possible (from declaration-level to statement-level to
expression-level).
Graphically:

The nodes at the top are call stack frames. The black arrows are function calls, the red arrows represent errors going up (left in the diagram) as the call stack is unwound.
The Environment
The environment is the center of the compiler’s universe: it’s the database that stores all information about user-written code.
Externally, the Env module exports an env type and some functions. The
environment has a simple CRUD API, and environment updates are functional:
inserting or modifying a record returns a new value of type env.
Internally, the environment is a collection of tables, with rows pointing at other rows in the same or other tables, kind of like a manual implementation of an SQL database. And like a typical SQL database, every object has a unique numeric ID that is automatically generated on insertion.
The tables are:
- The file table.
- The module table.
- The declaration table.
- The method table.
- The monomorph table.
The file table stores the paths and contents of the source files the compiler has read:
| ID | Path | Contents |
|---|---|---|
| 1 | src/Db.aui |
module Db is ... |
| 2 | src/Db.aum |
module body Db is... |
This is for error reporting: declarations, statements, and expressions have a code span, which is the file ID, start line/column, and end line/column where they appear. The error reporter can then retrieve the file record using the file ID, print the path, and use the contents string to show the source context the error happened in.
The module table contains information about user-defined modules:
| ID | Name | I. File | I. Docstring | B. File | B. Docstring | Kind | Imported Instances | Imports From |
|---|---|---|---|---|---|---|---|---|
| 1 | Db |
1 | "This module..." |
2 | "Internally, ..." |
Unsafe. | 2, 43, 93 | 3, 67, 21 |
The columns are:
- ID: the ID of the module.
- I. File: the ID of the module interface file.
- I. Docstring: the docstring of the module interface.
- B. File: the ID of the module body file.
- B. Docstring: the docstring of the module body (typically private implementation documentation).
- Kind: whether or not the module is unsafe.
- Imported Instances: the declaration IDs of the typeclass instances the module imports from.
- Imports From: the module IDs of the modules this module imports declarations from.
The declarations table is the most important. This stores every declaration: constants, records, unions, functions, typeclasses, and typeclass instances. Every declaration has:
- Its unique declaration ID,
- The ID of the module it is defined in,
- Visibility information (public/opaque/private for types, public/private for everything else), and
- A docstring for that declaration.
The other fields are declaration-specific. For the purposes of the environment, typeclass methods are considered declarations (since they can be exported and imported, and their names must not collide with other declaration names in the module).
The methods table contains the methods of typeclass instances. These are stored separately because it’s more convenient to have a flat structure, rather than a deeply nested one. Every record has a unique instance method ID, as well as the ID of the typeclass method it corresponds to.
Finally, the monomorphs table stores monomorphs: the result of instantating
a generic type or function with a given set of (monomorphic) type arguments. For
example, if you have a declaration of a generic type Foo[T: Free]: Free, and
the code mentions Foo[Unit], Foo[Int32], and Foo[MyType], the monomorphs
table will have an entry for each of these.
Import Resolution
The import resolution pass takes a list of import declarations and turns them
into a map from identifiers to qualified identifiers. That is, given something
like:
import Foo (a)
import Bar (b as bb);
We get a map like this:
| Local Name | Source Module | Original Name |
|---|---|---|
a |
Foo |
a |
bb |
Bar |
b |
The “local name” or “nickname” of a declaration is the name used in the importing module, while the original name is the name of that declaration in the module it is defined in.
Import resolution checks a number of things: it checks that the declarations we’re importing have public or opaque visibility, and that imports don’t collide with each other.
The Abstract Syntax Tree
The abstract syntax tree is mostly identical to the CST, with two differences:
First, identifiers are qualified: they carry information about which module they’re part of, either the local module or some other module they were imported from.
Second, the node that represents let statements contains a body. So in the
CST, the following:
let x: T := y;
foo(x);
bar(x);
baz(x);
Is represented as a sequence of nodes, in the AST, the scope where x is
defined gets folded into the let node itself, so that if it were represented
as code, it would look like:
let x: T := y in
foo(x);
bar(x);
baz(x);
end let;
Abstraction Pass
In the abstraction pass, the CST becomes an AST. This isn’t terribly involved. Mostly two things happen:
letreshaping: the scope in which the variable(s) defined in aletare live is put inside theletstatement node, to make future code easier.- Identifiers are qualified: using the import map in the import resolution section, identifiers (which are just strings) get source information added to them, whether they’re from this module or imported from elsewhere.
Extraction Pass
The extraction pass takes a combined module, and inserts its declarations into the environment. This is where most of the rules around declarations are checked for correctness.
For example, extracting a typeclass instance performs the following checks:
(* ... *)
(* Check the argument has the right universe for the typeclass. *)
let _ = check_instance_argument_has_right_universe universe argument in
(* Check the argument has the right shape. *)
let _ = check_instance_argument_has_right_shape typarams argument in
(* Check that the none of the type parameters in the generic instance
collide with the type parameter of the typeclass. *)
let _ = check_disjoint_typarams typeclass_param_name typarams in
(* Local uniqueness: does this instance collide with other instances in this module? *)
let _ =
let other_instances: decl list =
List.filter (fun decl ->
match decl with
| Instance { typeclass_id=typeclass_id'; _ } ->
equal_decl_id typeclass_id typeclass_id'
| _ -> false)
(module_instances env mod_id)
in
check_instance_locally_unique other_instances argument
in
(* Global uniqueness: check orphan rules. *)
let _ = check_instance_orphan_rules env mod_id typeclass_mod_id argument in
(* ... *)
Linked Representation
The linked representation is essentially the same as the AST, except the declarations carry a declaration ID, so subsequent code that easily find the corresponding declaration in the environment.
Typing Pass
Other than the environment, the typing pass is the most important part of the compiler. And it’s a big mess. The code quality is solidly 4/5 Cthulhus. Mostly because the functions have accumulated context parameters so gradually that I never noticed, so many of the functions have four or five parameters they have to pass all the way down.
Conceptually, the way it works is very simple: the typing pass recurs down the AST, and from the bottom up, turns every AST node into a TAST node, the TAST being essentially the same as the AST but some1 nodes now carry type information.
Linearity Checking
Described here.
Monomorphization
A monomorphic type is a type with no type variables. A monomorphic function is a function with no generic type parameters. Monomorphization is the process of turning Austral code with generics into monomorphic code without.
For example, given some code with a generic type:
module body Foo is
record Box[A: Free]: Free is
val: A;
end;
function foo(): Unit is
let b1: Box[Unit] := Box(val => nil);
let b2: Box[Int32] := Box(val => 10);
let b3: Box[Box[Int32]] := Box(val => b2);
return nil;
end;
end module body.
After monomorphization, the code would look something like this:
module body Foo is
record Box_Unit: Free is
val: Unit;
end;
record Box_Int32: Free is
val: Int32;
end;
record Box_Box_Int32: Free is
val: Box_Int32;
end;
function foo(): Unit is
let b1: Box_Unit := Box_Unit(val => nil);
let b2: Box_Int32 := Box_Int32(val => 10);
let b3: Box_Box_Int32 := Box_Int32_Int32(val => b2);
return nil;
end;
end module body.
And the transformation is analogous for generic functions.
Monomorphization of generic types works recursively from the bottom up. To transform a type to a monomorphic type:
- If encountering a type with no type arguments, leave it alone.
- If encountering a generic type with (monomorphic) type arguments applied to it, retrieve or add a monomorph for the given type and arguments, and replace this type with the monomorph.
To see how the algorithm works, consider this hypothetical generic type:
Map[String, Pair[Position, List[String]]]
Initially, the table of monomorphs is empty.
Step by step:
Stringis left unchanged.-
List[String]is added to the table of monomorphs:ID Type Arguments 1 ListString - The type is now:
Map[String, Pair[Position, Mono(1)]] Positionis left unchanged.-
Pair[Position, Mono(1)is added to the table:ID Type Arguments 1 ListString2 PairPosition,Mono(1) - The type is now:
Map[String, Mono(2)] -
Map[String, Mono(2)]is added to the table:ID Type Arguments 1 ListString2 PairPosition,Mono(1)3 MapString,Mono(2) - The type is now
Mono(3).
Monomorphization of functions is analogous: starting from the main function
(which has no generic type parameters), recur down the body. If we encounter a
call to a generic function f, look at the concrete type arguments the function
is being called with. These define a mapping from the function’s type parameters
{T_0, ..., T_n} to the type arguments {t_0, ..., t_n}. For example, the
mapping might look like {T => Int32, U => Box[Bool] }.
Then, essentially, create a new function, and do a search-and-replace of the
function’s body, replacing every T_i with its corresponding t_i. This
process happens recursively.
Backend
The backend is very simple: it spits out C code. There’s a group of types to represent C ASTs, the monomorphic AST gets transformed into a C AST by the code generation step. The codegen is very simple given that monomorphized Austral is very close to C, pretty much the only feature Austral has that C doesn’t is tagged unions.
It used to be the backend was C++, and generic Austral functions and generic typeclass instances were compiled to templated C++ functions. That meant I didn’t have to implement monomorphization myself (which was a huge pain in the ass) but it created these inscrutable bugs due to the subtle differences between the two type systems. It also covered up bugs in type-checking and typeclass resolution that would have shown up had I implemented monomorphization. So I ended up changing the backend to straightforward C and implementing monomorphization in OCaml.
C Representation
The C AST is defined by the types in the CRepr module. This is more or less
what you’d expect, for example, the type of C expressions is:
type c_expr =
| CBool of bool
| CInt of string
| CFloat of string
| CString of escaped_string
| CVar of string
| CFuncall of string * c_expr list
| CFptrCall of c_expr * c_ty * c_ty list * c_expr list
| CCast of c_expr * c_ty
| CArithmetic of arithmetic_operator * c_expr * c_expr
| CComparison of comparison_operator * c_expr * c_expr
| CConjunction of c_expr * c_expr
| CDisjunction of c_expr * c_expr
| CNegation of c_expr
| CIfExpression of c_expr * c_expr * c_expr
| CStructInitializer of (string * c_expr) list
| CStructAccessor of c_expr * string
| CPointerStructAccessor of c_expr * string
| CIndex of c_expr * c_expr
| CAddressOf of c_expr
| CEmbed of c_ty * string * c_expr list
| CDeref of c_expr
| CSizeOf of c_ty
The types for C type specifiers, statements, and declarations are defined analogously.
Code Generation
Code generation is mostly a one-to-one map from the monomorphic AST to the C AST. The function that codegens expressions makes this clear:
let rec gen_exp (mn: module_name) (e: mexpr): c_expr =
let g = gen_exp mn in
match e with
| MNilConstant ->
CBool false
| MBoolConstant b ->
CBool b
| MIntConstant i ->
CInt i
| MFloatConstant f ->
CFloat f
| MStringConstant s ->
CFuncall (
"au_make_array_from_string",
[
CString s;
CInt (string_of_int (String.length (escaped_to_string s)))
]
)
| MConstVar (n, _) ->
CVar (gen_qident n)
| MParamVar (n, _) ->
CVar (gen_ident n)
| MLocalVar (n, _) ->
CVar (gen_ident n)
| MGenericFunVar (id, _) ->
CCast (CVar (gen_mono_id id), fn_type)
| MConcreteFunVar (id, _) ->
CCast (CVar (gen_decl_id id), fn_type)
| MConcreteFuncall (id, _, args, _) ->
CFuncall (gen_decl_id id, List.map g args)
| MGenericFuncall (id, args, _) ->
CFuncall (gen_mono_id id, List.map g args)
| MConcreteMethodCall (id, _, args, _) ->
CFuncall (gen_ins_meth_id id, List.map g args)
| MGenericMethodCall (_, id, args, _) ->
CFuncall (gen_mono_id id, List.map g args)
...
The only thing that is different is the one feature monomorphic Austral (i.e., Austral with all generic functions and typeclass instances monomorphized) has that C does not: tagged unions.
An Austral union like this:
union OptionalInt: Free is
case Present is
value: Int32;
case Absent;
end;
Gets compiled into something like this:
enum OptionalInt_tag {
PRESENT,
ABSENT
}
typedef struct {
OptionalInt_tag tag;
union {
struct { int32_t value; } Present;
struct {} Absent;
} data;
} OptionalInt;
Then, a case statement like:
let opt: OptionalInt := Present(value => 123);
case opt of
when Present(value: Int32) do
-- Do something with `value`.
when Absent do
-- Do something else.
end case;
Gets compiled into:
switch (opt.tag) {
case OptionalInt_tag.PRESENT:
int32_t value = opt.data.Present.value;
/* Do something with `value`. */
break;
case OptionalInt_tag.ABSENT:
/* Do something else. */
break;
}
Something I want to improve in the future: right now each monomorph gets compiled to a function with the monomorph ID as the name, e.g.:
int mono_12() {
...
}
I’d like to add some more metadata to the compiled code, so there’s at least a comment above the function that says which function or typeclass method this monomorph points to, and the type arguments it was called with.
C Rendering
And as if the compiler wasn’t braindead enough, the last step of code generation is literally string concatenation: the C AST gets turned into a string. This process is called rendering.
Ideally the compiled C code should be readable, which means it has to be
indented. Rather than handle the string padding when rendering the C AST, the
rendering process returns a list of line values, which have an indentation
count and a string of the actual contents of that line, e.g.:
and render_stmt (i: indentation) (stmt: c_stmt): line list =
match stmt with
| CLet (name, ty, value) ->
let s = (render_type ty) ^ " " ^ name ^ " = " ^ (e value) ^ ";" in
[Line (i, s)]
| CAssign (lvalue, value) ->
let s = (e lvalue) ^ " = " ^ (e value) ^ ";" in
[Line (i, s)]
| CDiscarding value ->
[Line (i, (e value) ^ ";")]
| CIf (c, t, f) ->
List.concat [
[Line (i, "if (" ^ (e c) ^ ") {")];
render_stmt (indent i) t;
[Line (i, "} else {")];
render_stmt (indent i) f;
[Line (i, "}")]
]
Each line then gets turned into a string by turning its identation count i
into a string of with i space characters and prefixing it to the code:
let render_line (Line (Indentation i, s)) =
(String.make i ' ') ^ s
And then all the lines get concatenated together:
let rec render_unit (CUnit (name, decls)): string =
let rd d =
String.concat "\n" (List.map render_line (render_decl zero_indent d))
in
"/* --- BEGIN translation unit for module '" ^ name ^ "' --- */\n"
^ (String.concat "\n\n" (List.map rd decls))
^ "\n/* --- END translation unit for module '" ^ name ^ "' --- */\n"
Testing
The compiler has some OCaml tests that test the individual components directly. But because this is a bootstrapping compiler that is meant to evolve rapidly there’s few of these: they’d mostly be destroyed by large-scale refactoring.
Instead, most of the tests are end-to-end tests, where the compiler is treated as a black box.
Tests are stored in the test-programs/suites/ directory, each test
is a folder with some Austral code, and the test is essentially defined by the
files in that folder:
- If the code is meant to compile and run successfully, you just need a
Test.aumfile. - If the code is meant to compile, and run, and emit some specific output, you
need a
program-stdout.txtfile with the expected output. - If the code is meant to fail to compile, you need an
austral-stderr.txtfile with the expected compiler error message.
The test runner is a simple Python program that walks the test folder and executes every test it finds.
Future Work
In addition to many bug fixes, these are some things I plan to do with the compiler in the future:
- HTML Error Reporting: because terminals are incredibly anemic. I got the idea, of all things, from Inform 7, which is far from a normal programming language but their error output has always been lovely.
-
JSON Error Reporting: this is for the end-to-end tests. Right now, tests of programs that are expected to fail to compile just assert that the compiler produces a particular message. This is not robust to changes in the error reporting format. So I’d like to add JSON error reporting that just produces a reliably structured message for the end-to-end tests or for clients to parse the errors if they want to.
-
Separate Compilation: this will likely involve significant refactoring, but it will allow large programs to be compiled effectively by allowing compilation to happen in parallel and to pick up where it left off.
-
Literate Programming: I’m not sure whether this is a great idea or a terrible idea, but part of me wants to refactor the compiler into a literate program. This would help onboard more people, but it would also make the compiler’s source code into the most useful compilers textbook ever written, since there are so few textbooks that actually focus on the frontend (type checking, diagnostics, etc.) parts of a compiler, and so few that actually show you how to build a production-quality compiler.
Footnotes
-
“Some” because certain nodes don’t need to carry a type, e.g. the
nilconstant will always have typeUnit. ↩